- 5 سوال برای پرسیدن هنگام انتخاب بازار NFT
- نمودار خط واکنش
- Metatrader 4 و 5: تفاوت چیست؟
- سهام به هفته هرج و مرج درپوش که توسط ترس در مورد بانک ها هدایت می شود ، سقوط می کنند
- اندازه بازار پتروشیمیایی ، تجزیه و تحلیل تأثیرگذاری و COVID-19 ، بر اساس نوع (اتیلن ، زایلن ، پروپیلن ، متانول و دیگران) ، توسط صنعت استفاده نهایی (بسته بندی ، الکترونیک ، ساخت و ساز ، خودرو و سایر موارد) و پیش بینی منطقه ای ، 2021-2028
- معامله به جلو از ارز خارجی
- هزینه استفاده از یک کارگزار برای خرید یا فروش ملک چقدر است؟
- سود مرکب چگونه کار می کند (و چرا اهمیت دارد)
- چگونه کارگزاران وام مسکن کانادایی کار می کنند و راه هایی برای صرفه جویی در هزینه شما دارند
- پول هوشمند

آخرین مطالب
امکانات وب


بسیاری از افرادی که با دادههای سری زمانی کار میکنند، مجموعه دادههای خوب و منظمی دارند. دادهها را میتوان هر چند ثانیه، یا هر میلیثانیه یا هر چیز دیگری که آنها انتخاب میکنند نمونهبرداری کرد، اما با نمونهبرداری منظم، به این معناست که زمان بین نقاط داده اساساً ثابت است. محاسبه مقدار متوسط نقاط داده در یک دوره زمانی مشخص در یک مجموعه داده معمولی یک پرس و جو نسبتاً خوب برای نوشتن است. اما برای کسانی که دادههای نمونهگیری منظمی ندارند، گرفتن میانگین نماینده در یک دوره زمانی میتواند یک پرسش پیچیده و زمانبر برای نوشتن باشد. زمانی که با دادههای نمونهگیری نامنظم کار میکنید، میانگینهای وزندار زمانی راهی برای به دست آوردن میانگین بیطرفانه هستند.
داده های سری زمانی به سرعت به سراغ شما می آیند و گاهی اوقات میلیون ها نقطه داده در ثانیه تولید می کنند (در مورد داده های سری زمانی بیشتر بخوانید). به دلیل حجم و سرعت بسیار زیاد اطلاعات، دادههای سری زمانی میتوانند برای پرس و جو و تجزیه و تحلیل پیچیده باشند، به همین دلیل است که ما TimescaleDB، یک پایگاه داده رابطهای چند گره، در مقیاس پتابایت، کاملا رایگان برای سریهای زمانی ساختیم.
نمونهبرداری نامنظم از دادههای سری زمانی فقط سطح دیگری از پیچیدگی را اضافه میکند – و رایجتر از آن چیزی است که فکر میکنید. برای مثال، دادههای نمونهگیری نامنظم و در نتیجه نیاز به میانگینهای وزندار زمانی، اغلب در موارد زیر رخ میدهد:
- اینترنت اشیاء صنعتی، که در آن تیمها دادهها را تنها با ارسال امتیاز زمانی که مقدار تغییر میکند، فشرده میکنند
- سنجش از راه دور، که در آن ارسال دادهها از لبه میتواند پرهزینه باشد، بنابراین شما فقط دادههای با فرکانس بالا را برای حیاتیترین عملیات ارسال میکنید.
- سیستمهای مبتنی بر ماشه، که در آن نرخ نمونهبرداری از یک حسگر تحتتاثیر خواندن حسگر دیگری قرار میگیرد (یعنی یک سیستم امنیتی که زمانی که یک حسگر حرکت فعال میشود، دادهها را بیشتر ارسال میکند)
- . و بسیاری، بسیاری دیگر
در Timescale، ما همیشه به دنبال راههایی برای آسانتر کردن زندگی توسعهدهندگان هستیم، بهخصوص زمانی که آنها با دادههای سری زمانی کار میکنند. برای این منظور، ما hyperfunction ها، توابع جدید SQL را معرفی کردیم که کار با داده های سری زمانی را در PostgreSQL ساده می کند. یکی از این بیش توابع به شما امکان می دهد میانگین های وزنی با زمان را به سرعت و کارآمد محاسبه کنید، بنابراین ساعت ها بهره وری به دست می آورید.
نمونههایی از میانگینهای وزندار زمانی، نحوه محاسبه آنها، نحوه استفاده از ابرتوابع میانگینهای وزندار زمانی در TimescaleDB، و چند ایده برای استفاده از آنها برای افزایش بهرهوری پروژههای خود، بدون توجه به دامنه، بخوانید..
اگر می خواهید با استفاده از Hyperfunction Time_weight - و بسیاری دیگر - بلافاصله ، یک سرویس TimescaledB کاملاً مدیریت شده را شروع کنید: یک حساب کاربری ایجاد کنید تا 30 روز آن را به صورت رایگان امتحان کنید. Hyperfunctions در هر سرویس جدید پایگاه داده در TimeScale Forge از قبل بارگذاری شده است ، بنابراین پس از ایجاد یک سرویس جدید ، همه شما قرار است از آنها استفاده کنید.
اگر ترجیح می دهید نمونه های پایگاه داده خود را مدیریت کنید ، می توانید برنامه افزودنی TimeScaledB_ToolKit را در GitHub بارگیری و نصب کنید ، پس از آن می توانید از Time_weight و سایر عملکردهای مختلف استفاده کنید.
سرانجام ، ما عاشق ساختن در عمومی هستیم و به طور مداوم در حال بهبود است:
- اگر در مورد این پست وبلاگ سؤال یا نظر دارید ، ما در صفحه GitHub ما بحثی را شروع کرده ایم و دوست داریم از شما بشنویم.(و اگر آنچه را که می بینید دوست دارید ، GitHub ⭐ همیشه مورد استقبال و استقبال قرار می گیرید!)
- شما می توانید نقشه راه آینده ما را در مورد GitHub برای لیستی از ویژگی های پیشنهادی ، و همچنین ویژگی هایی که در حال حاضر اجرا می کنیم و مواردی که امروزه برای استفاده در دسترس هستند مشاهده کنید.
میانگین های وزنی زمان چیست؟
من بیش از 3 سال است که یک توسعه دهنده در Timescale بوده ام و حدود 5 سال در پایگاه داده ها کار کردم ، اما من قبل از آن یک الکتروشیمیست بودم. من به عنوان یک الکتروشیمیست ، من برای تولید کننده باتری کار کردم و نمودارهای زیادی مانند این را دیدم:

به عنوان مثال منحنی تخلیه باتری ، که توصیف می کند باتری چه مدت می تواند چیزی را تأمین کند.(همچنین یک نمونه اصلی از میانگین های دارای وزن زمان لازم است) از https://www. nrel. gov/docs/fy17osti/67809. pdf مشتق شده است
این یک منحنی تخلیه باتری است ، که توصیف می کند که یک باتری چه مدت می تواند چیزی را تأمین کند. محور X ظرفیت را در ساعتهای AMP نشان می دهد ، و از آنجا که این یک تخلیه جریان ثابت است ، محور x واقعاً فقط یک پروکسی برای زمان است. محور y ولتاژ را نشان می دهد ، که میزان توان باتری را تعیین می کند. با ادامه تخلیه باتری ، ولتاژ کاهش می یابد تا زمانی که به جایی برسد که نیاز به شارژ مجدد داشته باشد.
هنگامی که ما برای فرمولاسیون باتری جدید تحقیق و توسعه می کنیم ، بارها و بارها باتری ها را چرخه می دهیم تا بفهمیم کدام فرمول ها باتری را طولانی ترین طول می کشد.
اگر بیشتر به منحنی تخلیه نگاه کنید ، متوجه خواهید شد که فقط دو بخش "جالب" وجود دارد:

به عنوان مثال منحنی تخلیه باتری ، "بیت های جالب" را صدا می کند (نقاطی در زمان که داده ها به سرعت تغییر می کنند)
این قسمت ها در ابتدا و انتهای تخلیه است که ولتاژ به سرعت تغییر می کند. بین این دو بخش ، آن دوره طولانی در وسط وجود دارد ، جایی که ولتاژ به سختی تغییر می کند:

مثال منحنی تخلیه باتری، فراخوانی "بیت های خسته کننده" (نقاط زمانی که داده ها نسبتاً ثابت می مانند)
حالا که قبلاً گفتم الکتروشیمی هستم، اعتراف می کنم که کمی اغراق کردم. من آنقدر در مورد الکتروشیمی می دانستم که خطرناک باشد، اما با افرادی که دکترا داشتند کار کردم که خیلی بیشتر از من می دانستند.
اما، من اغلب در کار با داده ها بهتر از آنها بودم، بنابراین کارهایی مانند برنامه نویسی پتانسیواستات، قطعه ای از تجهیزاتی که باتری را به آن وصل می کنید تا این آزمایش ها را انجام دهید، انجام می دادم.
برای بخشهای جالب چرخه تخلیه (آن قسمتها در ابتدا و انتهای)، میتوانیم نمونه پتانسیواستات را با حداکثر نرخ آن، معمولاً یک نقطه در هر 10 میلیثانیه یا بیشتر داشته باشیم. ما نمیخواستیم تعداد زیادی از نقاط داده را در طول قطعات طولانی و خستهکننده که ولتاژ تغییر نمیکند نمونهبرداری کنیم، زیرا این به معنای صرفهجویی در مقدار زیادی داده با مقادیر غیرقابل تغییر و هدر رفتن فضای ذخیرهسازی است.
برای کاهش دادههای خستهکنندهای که باید بدون از دست دادن بیتهای جالب با آن سروکار داشته باشیم، برنامه را طوری تنظیم میکنیم که هر 3 دقیقه یکبار، یا زمانی که ولتاژ به مقدار معقولی تغییر میکند، مثلاً بیش از 5 میلیولت، نمونهبرداری کند.
در عمل، چیزی شبیه به این است:

مثال منحنی تخلیه باتری با نقاط داده روی هم قرار گرفته تا نمونه برداری سریع را در طول بیت های جالب و نمونه برداری کندتر را در طول بیت های خسته کننده نشان دهد.
با نمونهبرداری از دادهها به این روش، دادههای بیشتری در قسمتهای جالب و دادههای کمتری در بخش میانی خستهکننده دریافت میکنیم. عالیه!
این به ما اجازه میدهد به سؤالات جالبتری درباره تغییرات سریع بخشهای منحنی پاسخ دهیم و تمام اطلاعاتی را که در مورد بخشهایی که به آهستگی تغییر میکنند - بدون ذخیره کردن دادههای اضافی، در اختیار ما قرار داد. اما، در اینجا یک سوال وجود دارد: با توجه به این مجموعه داده، چگونه ولتاژ متوسط را در حین تخلیه پیدا کنیم؟
این سوال مهم است زیرا یکی از مواردی بود که میتوانستیم بین این منحنی تخلیه و منحنیهای آینده مقایسه کنیم، مثلاً 10 یا 100 سیکل بعد. با بالا رفتن سن باتری، متوسط ولتاژ آن کاهش می یابد و میزان کاهش آن در طول زمان می تواند به ما بگوید که ظرفیت ذخیره سازی باتری در طول چرخه عمر آن چقدر خوب است - و آیا می تواند به محصول مفیدی تبدیل شود.
مشکل این است که دادههای موجود در بیتهای جالب بیشتر نمونهبرداری میشوند (یعنی نقاط داده بیشتری برای بیتهای جالب وجود دارد)، که به هنگام محاسبه میانگین وزن بیشتری به آن میدهد، حتی اگر اینطور نباشد.

به عنوان مثال منحنی تخلیه باتری ، با نقاط داده های مصور نشان می دهد که در حالی که ما داده های بیشتری را در طول بیت های جالب جمع می کنیم ، آنها نباید "اضافی" را حساب کنند.
اگر ما فقط یک میانگین ساده لوحانه را در کل منحنی گرفتیم ، مقدار را در هر نقطه اضافه می کنیم و بر اساس تعداد امتیاز تقسیم می کنیم ، این بدان معنی است که تغییر در نرخ نمونه برداری ما می تواند میانگین محاسبه شده ما را تغییر دهد. حتی اگر اثر اساسی واقعاً یکسان بود!
ما به راحتی می توانیم از هر یک از تفاوت هایی که سعی در شناسایی آن داشتیم غافل شویم - و هر سرنخ در مورد چگونگی بهبود باتری ها فقط می توانیم در تغییر پروتکل نمونه گیری خود از بین بروند.
حال ، برخی از افراد می گویند: خوب ، چرا فقط با حداکثر سرعت پتانسیلوستات ، حتی در قسمت های خسته کننده ، نمونه نمی گیریم؟خوب ، این آزمایشات تخلیه واقعاً طولانی شد. آنها 10 تا 12 ساعت طول می کشند ، اما بیت های جالب می توانند از ثانیه یا دقیقه بسیار کوتاه باشند. اگر ما با بالاترین نرخ نمونه برداری کنیم ، هر 10 میلی متر یا بیشتر ، این به معنای سفارش داده های بیشتر برای ذخیره سازی است حتی اگر به سختی از هیچ یک از آن استفاده کنیم! و سفارشات بزرگی داده های بیشتر به معنای هزینه بیشتر ، زمان بیشتر برای تجزیه و تحلیل ، انواع مشکلات است.
بنابراین سوال بزرگ این است: وقتی با نقاط داده های نامنظم فاصله کار می کنیم ، چگونه می توانیم نماینده را بدست آوریم؟
بیایید برای لحظه ای نظری در اینجا بگیریم:
. شما می خواهید از پیش بروید تا ببینید که چگونه از میانگین وزن زمان استفاده می شود ، بیت های ماتی در اینجا به پایان می رسند.)
MATHY BITS: چگونه می توان میانگین وزنی را به دست آورد
بیایید بگوییم ما نکاتی مانند این را داریم:

یک مجموعه داده نظری ، به طور نامنظم نمونه برداری سری زمانی
سپس ، میانگین عادی مجموع مقادیر است که بر اساس تعداد کل امتیازات تقسیم می شود:
اما ، از آنجا که آنها به طور نامنظم فاصله دارند ، ما به راهی برای پاسخگویی به آن نیاز داریم.
یکی از راه های فکر کردن در مورد آن این است که در هر مقطع زمانی ارزش کسب کنید و سپس آن را با کل زمان تقسیم کنید. این امر مانند بدست آوردن مساحت کل در زیر منحنی و تقسیم بر کل زمان Δt خواهد بود.

منطقه تحت مجموعه داده های سری زمانی نامنظم نمونه برداری
(در این حالت ، ما در حال انجام درون یابی خطی بین نقاط هستیم). بنابراین ، بیایید روی یافتن آن منطقه تمرکز کنیم. منطقه بین دو نقطه اول یک ذوزنقه است:

یک ذوزنقه که نماینده منطقه در دو نقطه اول است
که واقعاً مستطیل به علاوه مثلث است:
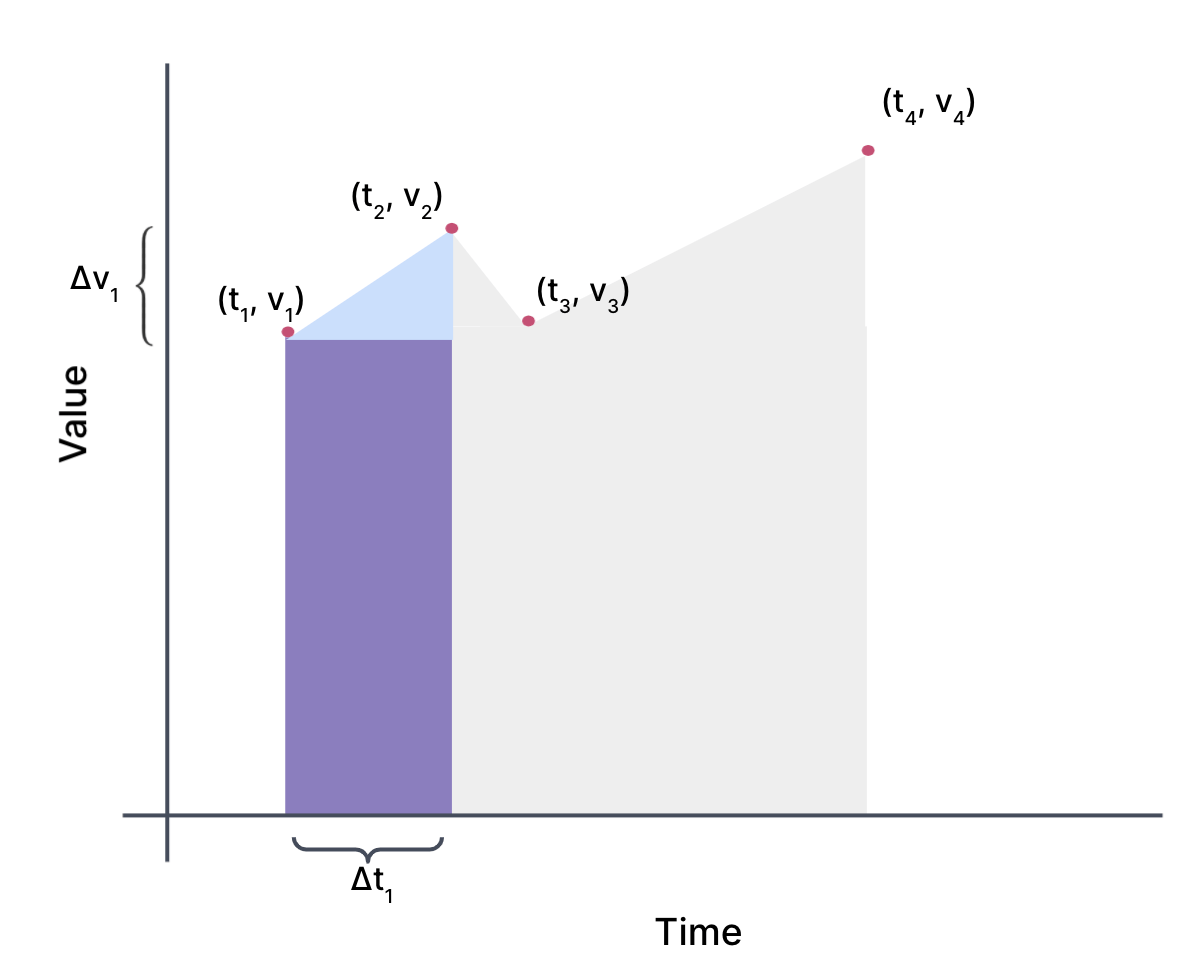
همان ذوزنقه به یک مستطیل و مثلث شکسته شد.
خوب ، بیایید آن منطقه را محاسبه کنیم:
بنابراین فقط برای روشن شدن ، این:
باشه. بنابراین اگر متوجه آن شویم:
شروع delta v_1 = v_2 - v_1 end
ما می توانیم این معادله را به خوبی ساده کنیم:
نکته جالب توجه این است که این روش جدیدی برای فکر کردن در مورد این راه حل به ما می دهد: این میانگین هر جفت از مقادیر مجاور است که تا زمان بین آنها وزن دارد:
همچنین برابر با منطقه مستطیل کشیده شده به نقطه میانی بین V1 و V2 است:

مساحت ذوزنقه و مستطیل ، که به نقطه میانی بین دو نقطه کشیده شده است ، یکسان است.
اکنون که فرمول را برای دو نقطه مجاور به دست آورده ایم ، می توانیم این را برای هر جفت از نقاط مجاور در مجموعه داده ها تکرار کنیم. سپس تنها کاری که ما باید انجام دهیم این است که جمع بندی کنید ، و این مبلغ وزنی زمان خواهد بود که برابر با منطقه زیر منحنی است.(مردمی که محاسبه را مطالعه کرده اند ، در واقع ممکن است برخی از این موارد را از زمانی که در مورد انتگرال ها و تقریب های انتگرال یاد می گرفتند به خاطر بسپارند!)
با کل مساحت زیر منحنی محاسبه شده ، تنها کاری که باید انجام دهیم این است که مبلغ زمان وزن را بر اساس ΔT کلی تقسیم کنیم و میانگین وزن خود را داریم. استراتژی برای تحلیل فاندمنتال...

ما را در سایت استراتژی برای تحلیل فاندمنتال دنبال می کنید
برچسب : نویسنده : سعید شیخزاده بازدید : 50
آرشیو مطالب
لینک دوستان
- کرم سفید کننده وا
- دانلود آهنگ جدید
- خرید گوشی
- فرش کاشان
- بازار اجتماعی رایج
- خرید لایسنس نود 32
- هاست ایمیل
- خرید بانه
- خرید بک لینک
- کلاه کاسکت
- موزیک باران
- دانلود آهنگ جدید
- ازن ژنراتور
- نمایندگی شیائومی مشهد
- مشاوره حقوقی تلفنی با وکیل
- کرم سفید کننده واژن
- اگهی استخدام کارپ
- دانلود فیلم
- آرشیو مطالب
- فرش مسجد
- دعا
- لیزر موهای زائد
- رنگ مو
- شارژ
خبرنامه
